
Linked Data builds on the foundations of the web to make data findable, connected and reusable. It emerged from the need to move beyond static files and silos, where information was hard to share, combine or keep up to date. By applying web principles to data itself, Linked Data turns isolated datasets into a living web of information – a foundation for reliable analysis, integration and innovation.
What does that actually mean? Aren’t PDFs or spreadsheets “publishing data”?
If your goal is for people to read a report, a PDF or web page is fine. But the data inside is effectively locked up. Others can’t reliably extract it, combine it with their own sources, or keep it up‑to‑date without manual effort. Publishing a spreadsheet helps a bit – the data can be analysed – but you still get static silos. Each file is an island with unspoken assumptions: column meanings, codes, units and versions aren’t machine‑understandable. There’s no safe way to connect one sheet to the next, filter only what you need, or get timely updates without re‑downloading and reconciling changes.
What makes Linked Data different?
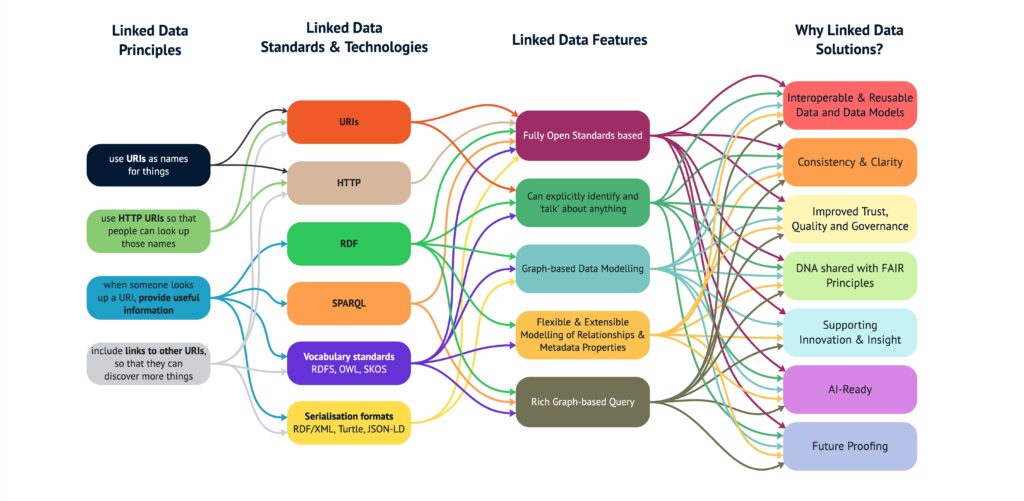
Linked Data applies core web principles to the data itself:
- Stable identifiers (URIs) for things
Every real‑world thing — a school, a river, a species, a price index — gets its own web address. - Structured statements about those things
Each URI is described with small, machine‑readable facts (name, location, category, status). - Links to related things
Statements point to other URIs (e.g. a school’s local authority, catchment, inspection rating), forming a navigable web of data. - Open web standards
Use JSON‑LD/RDF over HTTP, with SPARQL/filtered APIs for slices and updates, plus versioning and provenance.
Example: If we publish UK schools as Linked Data, each school has a URI. It’s described with its name, address and coordinates, and links to the URI of its local authority. The authority in turn links to its boundary and budget data. Applications can follow those links, combine them safely, and stay in sync as data changes.
Why it’s better
(in practice)
Trust and quality
- In context: Every item has a resolvable web address you can cite, annotate and explain.
- Auditable: Built-in provenance, versions and change histories reduce risk.
Access and integration
- Safely combinable: Shared vocabularies and links make integration across datasets predictable.
- Fine-grained access: Get just the slice you need (by area, time, type) without moving whole files.
- Always current: Apps can read from the live graph and still download snapshots when needed.
Future-proofing
- AI-ready: Clear semantics make the data discoverable and useful for modern analytics and LLMs.
- Reusable and extensible: Start small and grow. Add new data, vocabularies, or links over time without breaking what’s already there. Existing applications can continue to reuse the data while new uses and insights emerge.
- Open and standardised: Built on widely adopted W3C standards and web protocols, Linked Data avoids proprietary formats and reduces the risk of vendor lock-in, ensuring long-term accessibility and interoperability.
Linked Data and FAIR Data
The FAIR principles – Findable, Accessible, Interoperable, Reusable – are now widely adopted across research, government and industry. Linked Data directly supports them:
- Findable: Each entity has a stable URI, making it uniquely citable and searchable on the web.
- Accessible: Standard web protocols (HTTP, APIs, SPARQL) allow open and controlled access.
- Interoperable: Common vocabularies and links mean data can be connected across domains and systems.
- Reusable: Rich metadata, provenance, and versioning ensure data can be safely reused in new contexts.
By design, Linked Data provides a practical, standards-based path to making data truly FAIR.
Want to know more about the advantages of Linked Data? Take a look at our companion page: Why Linked Data.
Why Linked Data
Talk to us about how we can bring the benefits of linked data to your organisation
The Building Blocks of Linked Data
The power of Linked Data comes from its foundations in open web standards.
These standards ensure that data isn’t trapped in bespoke formats or systems, but can be shared, linked and reused reliably. They provide a common language for describing things, giving them stable identifiers, and publishing them in ways that both people and machines can understand.
By building on these standards, Linked Data inherits the scalability of the web itself — enabling datasets to interconnect across organisations, domains and even countries.
URIs
URIs are used to identify anything of interest in the data, including the entities the data is about (e.g. a particular school), the classes or concepts involved in the data (e.g. the notion of a School) and the properties that are available to describe schools (e.g. its name, location, or controlling authority). While we tend to talk about URIs, which include various different identifier schemes, the recommendation is to use http URLs so that standard web client software can fetch (GET) from those URLs and hope to discover useful information on them and onward links to other related data.
RDF
The recommended approach to representing the data itself is to use RDF the Resource Description Framework.
RDF presents information as a series of simple statements. Each statement (sometimes also called a triple) says that some subject has some property with some value. The subject of the statement is normally identified by a URI, as is the property or predicate being described. The value of the property, the object of the statement, can either be a literal value (a string or number for example) or it can be another URI.
For example we might make a statement about the name of the school:

where so: 401874 represents the URI https://education.data.gov.uk/id/school/401874 and rdfs:label represents the URI https://www.w3.org/2000/01/rdf-schema#label The things being described and linked in these statements are typically called resources, hence the name Resource Description Framework. Thus RDF is intrinsically well-suited to the linked data approach of linking together things identified by URIs.
Apart from its simplicity and the fact that it is fundamentally based on identifying resources through use of URIs, RDF has one other key characteristic that makes linked data work well – it is schemaless or open world. When representing data using object oriented modelling such as UML or in common database design methods one thinks in terms of data as being held in containers (objects or rows of values). To publish, store or query such data you need to know what the allowed values are in the containers. In contrast, in RDF everything is represented as statements. Whether the statements are about attributes, such as a label, or relational links such as hasAdministrator, there is no similar notion of a fixed shape container. This means there is no requirement to do a global, top-down schema design to agree, for example, everything that can be said about a school. Instead different authorities are free to publish different statements about the same school using their own sets of properties. This gives an intrinsic flexibility and resilience to data published this way. However, we still need some way of publishing agreed on vocabularies of terms that can be used.
Vocabulary standards – RDFS, OWL, SKOS
To complement this open world use of terms we do need some way to publish vocabularies that define what terms are available and how those terms relate. These might range from simple controlled lists of terms, such as might be used in a library for categorizing documents, through to rich logical models of a domain. The formal term for such a shared, well specified vocabulary is an ontology. Though in linked data the level of formality and depth of modelling can vary widely according to the needs of a particular application.
Of course, we identify the class by a URI such as https://education.data.gov.uk/def/school/School not by its label. We commonly shorten URIs by defining a common prefix for a set of terms, so that if we use school: to represent the prefix https://education.data.gov.uk/def/school/ then the earlier URI would be shown as school:School.
At heart this approach to modelling is quite straightforward. We want to represent the types or categories into which our resources can be grouped, these are called classes.
So for example in defining an ontology to represent school information we might have a class called School. Similarly we need properties that can be used to link a resource to another resource or to a simple literal value. Again we use URIs to identify these properties, for example the rdfs:label used in the above example is a standard way of attaching a name or text label to any resource.
The standards that support this provide for a range of sophistication from simply listing classes and properties, through to expressing rich axioms that define relationships between the classes and properties. RDFS, the RDF Vocabulary Language (misleadingly the ‘S’ originally stood for ‘schema’), provideds a base foundation. In particular it defines terms such as rdf:type which links a resource to its class. Then OWL, the Web Ontology Language, provides more sophisticated capabilities on top of this.
In some situations we simply want a set of controlled terms that we are going to use as symbolic labels. They are not intended to model the domain in the way that the classes and properties do in RDFS and OWL. We simply want some way to denote a category separate from its textual label. The standard for that situation is SKOS or Simple Knowledge Organization System.
Other common vocabularies like PROV, ORG and Data-Cube have developed, and are commonly used.
SPARQL
The final key piece of the puzzle is the query. If we publish data as linked data then there is a certain amount that can be achieved by following your nose – that is starting from the URI of one resource, fetching it and following links to other resources. However, in many situations we want to actually query some aggregation of this data – to find all resources matching some pattern. For this we need a query language suited to this graph-like connected web of data. That query language is SPARQL.
Semantic Web
This technology stack was originally developed as part of a W3C initiative called the semantic web. The initiative was sometimes mis-interpreted as rather top down, AI-like, approach to the whole web – which was not the case. Some people may use semantic web and linked data interchangeably, others emphasise that linked data is a particular pragmatic way of applying the technology stack. In our view the technology stack is a very solid, practical way of modelling, sharing and working with data on the web – whatever label you want to give it.