Background
There is ongoing work within both local and central government on publication of data on payments to suppliers. Initially such data is generally being published as raw spreadsheets but there is a desire to move towards publication using open web standards that facilitate combination and comparison of data. Such linked data approaches can offer a number of benefits which complement publication in raw spreadsheet form:
- each item of spend gains a web address which can be used to reference or to annotate the data (for example link it to explanatory notes, associated freedom-of-information requests or community discussions);
- combination and comparison of datasets is made easier through the use of common identifiers (URIs) to denote both entities (e.g. suppliers or local councils) and concepts (e.g. spending categories), those URIs can then link on to further related data;
- adapts to local needs, for example councils wishing to publish additional information on how payments relate to internal cost centres and associated services can do so without requiring redesign of some central schema;
- supports simple web APIs allowing developers to build value-added services and user interfaces on top of the data without being required to maintain their own up to date copies of each dump.
The Local e-Government Standards Body (LeGSB) together the Local Government Group’s data publishing programme have worked to establish guidance and patterns for using linked data in this domain, resulting (among other outcomes) in the general payments ontology described here.
This note describes the payments ontology, a vocabulary to allow spend data to be represented in linked data format. It is aimed at practitioners who:
- know something about linked data already but are not necessarily experts,
- want to publish some spending information using the payments ontology, perhaps experimentally or perhaps as part of developing reusable tooling and processes for others to follow.
It may also be of use to developers wishing to consume and process linked data published by others.
For practitioners who simply need to get their data published and have no technical interest in the details of linked data then this guide is not a suitable starting point. For those situations we anticipate a number of tools being available from suppliers, as third party services or using locally developed scripts.
We use Turtle notation for writing down example data. For those not familiar with this notation there are a number of tutorials available on the web such as RDF Intro (slide 67 to 78).
The payments ontology
The payments ontology has been developed as a general purpose vocabulary for representing organizational spending information and is not specific to government or local government applications.
An outline illustration of the structure of the ontology is shown below:
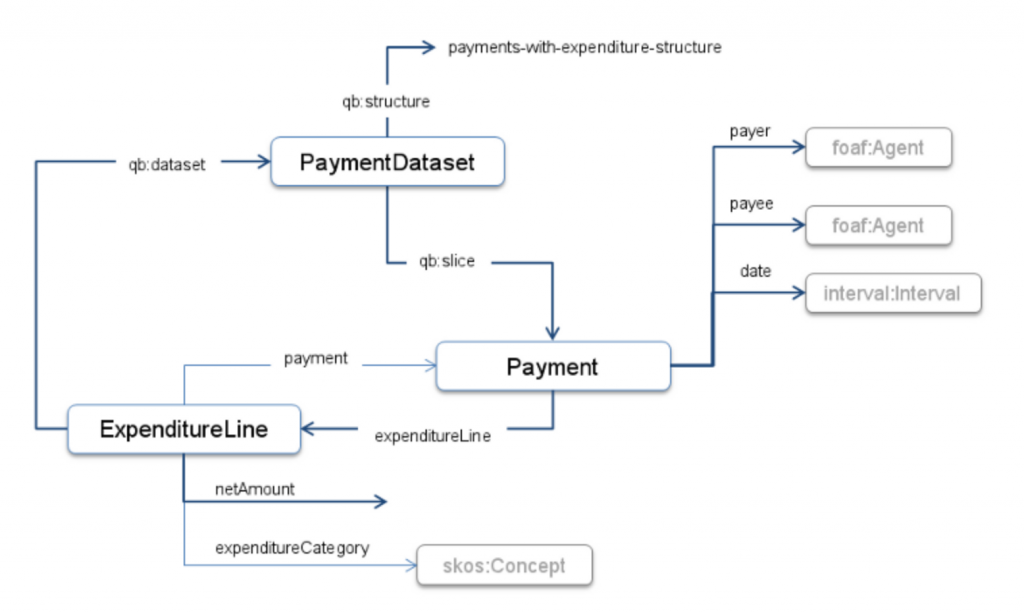
The ontology provides the ability to represent a set of payments, and has been designed to be flexible about the richness of the detail available. Consequently, there is a minimal mandatory structure, highlighted using the bold lines in the diagram, and optional properties which can be omitted if the information is not available for publication.
At the heart of the ontology is the concept of a Payment with an associated payer (e.g. the local authority making the payment), payee (e.g. the supplier receiving payment) and date. The payment can be further described by a number of optional properties including the part of the payer organization involved (unit), the collection of goods or services procured (purchase with associated narrative and procurementCategory) and links to resources documenting the process such as order, contract and invoice.
In most systems there will be an internal reference code which identifies the payment. When publishing the data as RDF it may be helpful to include that code (reference) to make it possible to trace back from queries on a published payment to the internal records which may help answer those queries.
Below each payment there is normally some form of “expenditure analysis” which defines how the payment is accounted for. A single payment may breakdown into a number of separate expenditure analysis lines. These lines can indicate the purpose for which goods or services were purchased (possibly down to individual cost centres within the payer’s organization) as well as item level details on what was purchased. This finer grain expenditure analysis need not always be included in a published data set but when it is we represent each analysis line using ExpenditureLine which is linked to the payment of which it is a part by the payment/expenditureLine pair of inverse properties. The individual expenditure lines include at least net cost (netAmount) and an associated expenditureCategory which defines the purpose of the purchase.
Above the individual payment is the notion of a PaymentDataset which is a collection of payment information. Metadata such as publication date or licensing information should be attached to the data set. The data set points to the set of payments it contains.
For a description of each term see the reference documentation
Namespace and prefix
The namespace for the ontology is: https://reference.data.gov.uk/def/payment#
Any of the property and type names in the diagram that don’t have a prefix (i.e. other than things like qb:structure) are in the payments namespace.
In the example data in the rest of the note we will use the prefix payment: for the payment namespace.
A note on data cubes
This section can be skipped by most readers, it is not necessary to understand data cubes or the data cube vocabulary in order to understand or work with the payments ontology.
Payments information is a particular case of a general representation, sometimes known as a data cube.
A data cube is a collection of observations laid out across some logical space. The collection can be characterized by a set of dimensions that define what the observation applies to (e.g. time) along with metadata describing what has been observed (referred to as measures), how it was measured and how the observations are expressed (e.g. units, multipliers, currency – referred to as attributes). We can think of such a data set as a multi-dimensional space, or hyper-cube, indexed by those dimensions. This space is commonly referred to as a cube for short; though the name shouldn’t be taken literally, it is not meant to imply that there are exactly three dimensions nor that all the dimensions are somehow similar in size.
There are standard approaches for representing data cubes. For example, in the realm of aggregate statistics the SDMX standard for data exchange incorporates a data cube representation at the heart of its information model. To enable such information to be published as linked data a data cube vocabulary has been developed.
The payments ontology is a specialization of the data cube vocabulary so that tools which understand linked-data data cubes can immediately process payments information (e.g. to offer appropriate graphical and tabular views of the data). In mapping the payments ontology into a data cube we treat a set of spend data as a collection of individual expenditures and regard payments as groups of expenditures (slices across the cube). One useful features of the data cube approach is that a dataset is annotated with metadata to explicitly define its structure (the dimensions, measures and attributes available). For the payments ontology that structure is predefined by the payments-with-expenditure-structure object which should be attached to each PaymentDataset via a qb:structure declaration.
Worked example
To illustrate the use of this ontology let us start with some example UK local government spend information and show how that looks when represented this way.
To make the initial example compact we’ll start with a dataset which provides only very basic payments information such as those from Spotlight on Spend, in particular the Elmbridge 01-04-2009 to 21-03-2010 data set.
The first few lines of this data looks like:

The first stage of mapping this data to the payments ontology is to determine if we have line level data or just payment level data. It may not be obvious just from these first few lines but the file name suggests it is line level data and indeed there are multiple rows with the same invoice ID.
Most of the mapping is fairly straight forward. Clearly the Payee column corresponds to payment:payee, Elmbridge itself is the payment:payer for all entries and the date and (net) amount are clear. This particular dataset doesn’t supply any information on the expenditure analysis itself, the nature of the procurement or any reference information. The Department column appears to correspond to an organizational unit of Elmbridge rather than to a generic expenditure category. So we have:
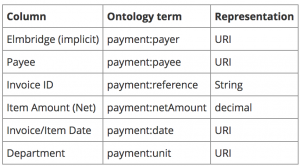
For most of these values we want to use URIs to represent them, in order to support linking of the information across datasets. We’ll come back (in the next section) to the details of those URIs and where they come from. The only surprising case might that of Date. We could use a literal value for the date (e.g. something of type xsd:date) but there are advantages to using URIs here too (see below).
Given this mapping then the first line of this data, when represented in RDF using the payment ontology, might look like:
<https://www.elmbridge.gov.uk/id/payment/HL00022825> a payment:Payment ; rdfs:label “Invoice HL00022825″@en ; payment:reference “HL00022825” ; payment:payer <https://www.elmbridge.gov.uk/id/elmbridge> ; payment:payee <https://www.elmbridge.gov.uk/id/payee/a-j-oakes-partners> ; payment:date <https://reference.data.gov.uk/id/day/2009-01-04> ; payment:expenditureLine <https://www.elmbridge.gov.uk/public/finance_line_level_data_01042009-31032010/expenditure0> ; payment:unit <https://www.elmbridge.gov.uk/id/department/leisure-and-cultural-services> . <https://www.elmbridge.gov.uk/public/finance_line_level_data_01042009-31032010/expenditure0> a payment:ExpenditureLine ; rdfs:label “Expenditure Line 0″@en ; qb:dataSet <https://www.elmbridge.gov.uk/public/finance_line_level_data_01042009-31032010> ; payment:payment <https://www.elmbridge.gov.uk/id/invoice/HL00022825> ; payment:netAmount 4000.0 .
Where we can also say, within the same RDF graph:
<https://www.elmbridge.gov.uk/id/elmbridge> owl:sameAs <https://statistics.data.gov.uk/id/local-authority/43UB> ; a org:FormalOrganization; rdfs:label “Elmbridge Borough Council”@en . <https://www.elmbridge.gov.uk/id/department/leisure-and-cultural-services> a org:OrganizationalUnit; rdfs:label “Leisure and Cultural Services”@en ; org:unitOf <https://www.elmbridge.gov.uk/id/elmbridge> . <https://www.elmbridge.gov.uk/id/elmbridge> org:hasUnit <https://www.elmbridge.gov.uk/id/department/leisure-and-cultural-services> . <https://www.elmbridge.gov.uk/id/payee/a-j-oakes-partners> a org:Organization ; rdfs:label “A J OAKES & PARTNERS”@en .
For completeness, here is a declaration of the overall dataset (we’ll come back to look at the details of such metadata in a later section):
<https://www.elmbridge.gov.uk/public/finance_line_level_data>
a void:Dataset ;
void:subset <https://www.elmbridge.gov.uk/public/finance_line_level_data_01042009-31032010> .
<https://www.elmbridge.gov.uk/public/finance_line_level_data_01042009-31032010>
a payment:PaymentDataset , void:Dataset , opmv:Artifact ;
# Basic metadata
rdfs:label "Elmbridge Borough Council Supplier Payments where transaction value is >= £500 for period April 2009 - March 2010"@en ;
dct:license <https://www.spotlightonspend.org.uk/DownloadTerms.aspx> ;
dct:created "2010-08-26"^^xsd:date ;
# Cube structure (statistical metadata)
qb:structure payment:payments-with-expenditure-structure ;
payment:currency <https://dbpedia.org/resource/Pound_sterling> ;
qb:sliceKey payment:payment-slice ;
# Provenance
dct:source <https://spotlightonspend-rawdata.s3.amazonaws.com/Elmbridge%20Borough%20Council%20line%20level%20data%2001042009%20-%2031032010.zip> ;
gridworks:wasExportedBy <https://www.elmbridge.gov.uk/public/finance_line_level_data_01042009-31032010_provenance#gridworks-export> ;
gridworks:wasExportedFrom <https://www.elmbridge.gov.uk/public/finance_line_level_data_01042009-31032010_provenance/gridworks-project.tar.gz> ;
# linked data metadata
void:vocabulary payment: , qb: ;
# Slices of the data
qb:slice <https://www.elmbridge.gov.uk/id/invoice/HL00022825>, ... ;
URI selection
Whenever we are generating linked data we face the issue of what URIs to use for each entity/concept. The payment ontology is largely neutral to the choice of URIs but some general advice in this area might be helpful.
The primary entities we need to identify in payments data are:
- the payer organization, e.g. a government department or a local authority
- any sub-units (departments) of the payer
- the payee organization
- the date of the payment
- the payments and expenditures themselves
The payer
Since the payer is (typically) the entity publishing the data they are in a position to create a URI for themselves (ideally one that can be dereferenced to obtain useful metadata) and use that to denote themselves within the dataset.
For the case of Local Authorities then proposals are being developed for how to standardize and support a lightweight approach to self-publication of such URIs, initiated and sponsored by LeGSB. This has the advantage that the authority themselves are then in full control of what authoritative information is published about them at that URI.
Alternatively, data.gov.uk provides a linked data version of ONS SNAC code database available from [SPARQL endpoint]. This supports URIs of the form:
https://statistics.data.gov.uk/id/local-authority/{snac}
where {snac} is the SNAC code for the authority.
A number of third parties also provide URIs for local authorities which dereference to RDF. In particular, dbpedia and OpenlyLocal.
Dbpedia provides URIs of the form https://dbpedia.org/resource/{name} where {name} is the title of the corresponding Wikipedia page.
OpenlyLocal provides URIs of the form https://openlylocal.com/id/councils/{nn} where {nn} is a code specific to OpenlyLocal, but also supports linked identifiers based on ONS and OS codings https://openlylocal.com/councils/snac_id/{snac} and https://openlylocal.com/councils/os_id/{OS-id}.
For the case of government departments there is also the option for a department to create a URI for itself in some appropriate stable namespace or to use the identifiers provided by data.gov.uk.
For the worked example we illustrated the self-publication option by using a URI within the Elmbridge domain: https://www.elmbridge.gov.uk/id/elmbridge even though that URI is not yet dereferencable.
Organizational units
For departments, or other sub-units, within the payer’s organization then external URIs are unlikely to exist so the publishing organization will need to create them. The simplest option is to adopt some URI convention with the payer’s namespace such as the one used in the worked example:
https://www.elmbridge.gov.uk/id/department/{normalized-department-name}
Ideally such URIs should be dereferencable and return information about the department. Depending on the publisher’s web infrastructure available resources this may or may not be practical. If it is not practical at this stage then that should not hold up publication of the data. The payment dataset itself can contain the relevant assertions about those departmental URIs:
<https://www.elmbridge.gov.uk/id/department/leisure-and-cultural-services> a org:OrganizationalUnit; rdfs:label "Leisure and Cultural Services"@en ; org:unitOf <https://www.elmbridge.gov.uk/id/elmbridge> . <https://www.elmbridge.gov.uk/id/elmbridge> org:hasUnit <https://www.elmbridge.gov.uk/id/department/leisure-and-cultural-services> .
The choice of URIs for organizations and organizational units is out of scope for this guide. Ideally organizations should be prepared to publish information about themselves so that those URIs dereference – either by use of redirections or, if necessary, by publishing a simple RDF file describing the organization and using fragment identifiers within that file to denote the organization and organizational subunits.
Supplier
The payee organization, i.e. the supplier, should ideally also be identified using common shared URIs. One aim for data.gov.uk is that it should provide reference URI sets for entities such as all UK companies and charities. However, such a reference URI set does not yet exist and in any case it would be unlikely to cover e.g. sole traders who are not VAT registered. A cross-local government group such as Knowledge Hub or SOCITM might step up to provide this. Third party organizations also offer relevant URI schemes – for UK Charities then OpenCharities provides dereferenceable URIs incorporating the charity number https://opencharities.org/charities/{charity-num}.
In absence of any definitive supplier identifier set then a good default option is for the publishing organization to assign URIs within a namespace under their own control. In this way publishing is decoupled and decentralized, each publisher can safely refer to local small organizations whose names are likely to be non-distinct (“AAAA Taxis”). As they, or third parties, find correspondences between supplier organizations mentioned by different payer organizations then those local names can be linked together or to more definitive URIs via owl:sameAs assertions.
This is the approach taken with the worked example:
<https://www.elmbridge.gov.uk/id/payee/a-j-oakes-partners> a org:Organization ; rdfs:label "A J OAKES & PARTNERS"@en .
In cases where a unique reference number is known for the supplier, but there is no corresponding supported URI, then this should be recorded in the dataset using org:identifier to enable merging of references.
Date of the payment
The date at which the payment was made could be represented by a simple literal value of type xsd:date or xsd:dateTime. However, the payments ontology requests that the date be represented as instances of interval:Interval such as those provided by the data.go.uk intervals URI set service. Using intervals allows us to say that a particular payment was made within a given month, financial quarter, year etc without having to specify the precise date on which it was made. This is useful for publishers who only wish to publish at such coarse resolutions but more importantly it allow us to identify, collect and aggregate payments within such intervals. A simple query is then able to find all payments which fall within a given period, such as government year, without having to embed logic to determine the inclusion.
The URI for a particular day follows a simple pattern:
https://reference.data.gov.uk/id/day/yyyy-mm-dd
As a convenience to data consumers it is good practice to include within the published dataset the basic metadata on those dates as could be obtained from the reference.data.gov.uk service. For example:
<https://reference.data.gov.uk/id/day/2009-01-04>
a interval:CalendarDay ;
rdfs:label "2009-01-04" ;
time:hasBeginning <https://reference.data.gov.uk/id/gregorian-instant/2009-01-04T00:00:00> ;
interval:ordinalYear 2009 ;
interval:ordinalMonthOfYear 01 ;
interval:ordinalDayOfMonth 04 ;
time:intervalDuring <https://reference.data.gov.uk/id/year/2009> ,
<https://reference.data.gov.uk/id/month/2009-01> ,
<https://reference.data.gov.uk/id/quarter/2009-Q1> ,
<https://reference.data.gov.uk/id/half/2009-H1>,
<https://reference.data.gov.uk/id/government-year/2008-2009> .
<https://reference.data.gov.uk/id/gregorian-instant/2009-01-04T00:00:00>
a time:Instant ;
time:inXSDDateTime "2009-01-04T00:00:00"^^xsd:dateTime .
The payments and expenditures
The individual payments and expenditure items within the data also need to be assigned URIs1. For payments we almost always have a transaction reference that provides an identifier which is unique within the boundaries of the payer’s organization. For expenditure analysis lines that we typically don’t have a direct identifier and so have to synthesize one – this might be based on row number within a source spreadsheet, sequence number in a database, line number within a containing payment or generation of unique string such as a UUID. We can then create a URI relative to either the payer’s organization or to the dataset URI.
In the worked example we used URIs relative to the dataset to represent expenditure lines:
https://www.elmbridge.gov.uk/public/finance_line_level_data_01042009-31032010/expenditure{n}
where {n} was in fact the row number in the source csv file.
It would also be possible to adopt a hash URI pattern:
https://www.elmbridge.gov.uk/public/finance_line_level_data_01042009-31032010#expenditure{n}
That has the advantage that if the full data file is published at https://www.elmbridge.gov.uk/public/finance_line_level_data_01042009-3103… then the URI is dereferencable. However, the dereference involves fetching the entire dataset which can overwhelm client applications. Using the slash URI patterns allows the possibility of publishing the data via a linked data publishing platform which can return individual expenditure descriptions upon dereference.
The same pattern of dataset-relative URIs could be used for payments:
https://www.elmbridge.gov.uk/public/finance_line_level_data_01042009-31032010/payment/{payment-reference}
or
https://www.elmbridge.gov.uk/public/finance_line_level_data_01042009-31032010#payment{payment-reference}
However, since payments do have a unique (for the payer) reference we chose a more global URI scheme in the worked example:
https://www.elmbridge.gov.uk/id/payment/{payment-reference}
This has the advantage of not being specific to the data set so that deferencing it might return a package of information on the payments aggregated across multiple sources (e.g. including annotations indicating associated Freedom of Information requests and responses).
Details and variations
In this section we expand upon the basic example and look at other aspects of spend information that we might be trying to publish and how they can be accommodated within or on top of the payments ontology.
Expenditure and procurement coding
An important piece of information on payments is what the purpose of the payment was (what part of the payers operation was the money spent on) and what the nature of the purchase was.
The organizational unit which made the purchase gives us some hint about the purpose of this but the internal organizational structure differs between organizations. To overcome this standardized schemes have been developed to enable expenditures by public sector organizations to be categorized in an organization-independent manner. Examples of such schemes include:
- The Best Value Accounting Code of Practice (BVACOP) subjective and objective categories from the The Chartered Institute of Public Finance and Accountancy.
- Public Sector Procurement Expenditure Survey codes from the Office of Government Commerce.
The payments ontology is intended to be open to the use of any such classification scheme. The scheme first needs to made available as a SKOS Concept Scheme. For categories which relate to the expenditure analysis then payment:expenditureCategory can be used to associate the category with the expenditure. It is possible to use multiple different coding schemes simultaneously since the URI for the category unambiguously identifies both the scheme and the particular category within it. For categories which relate specifically to the actual good or service purchased rather than the expenditure analysis the ontology supports the notion of a description of the thing purchased (payment:Purchase) which can be associated with a category and a narrative description.
Capital expenses
In many organizations it common to treat capital and revenue/expense funding separately. While there can be organization-specific subdivisions of these (e.g. different ring-fenced revenue accounts) the notion of capital as opposed to other expenditure is common across many organizations and legal jurisdictions. In the UK it is recognized for taxation purposes though defined by case law rather than by statute.
Since this categorization is so common we support it directly in the payments ontology by providing a SKOS concept scheme (payment:payment:expenditure-type) containing just two concepts (payment:capital and payment:revenue) which are both in that scheme as also typed as payment:ExpenditureType (a subclass of skos:Concept) for ease of access.
So we might have an expenditure:
<https://www.elmbridge.gov.uk/public/finance_line_level_data_01042009-31032010/expenditure1> a payment:ExpenditureLine ; rdfs:label "Expenditure Line 1 - capital payment for buildings"@en ; payment:expenditureCategory payment:capital ...
Redaction
When publishing payments information there is typically a need to redact some information (particularly names of some suppliers) for reasons of commercial confidentiality agreements, privacy, data protection and so forth. In text publications and spreadsheets such information may be marked by a text string such as “REDACTED”. When publishing as linked data such a text string can still be used but we can also indicate the redaction in a machine accessible way through the payment:Redaction class.
For example, if the name of a supplier has been redacted this can be described in the dataset using the pattern:
<payment-123> a payment:Payment;
payment:payee <supplier-123> .
<supplier-123> a org:Organization;
rdfs:label [ a payment:Redaction; rdfs:label "REDACTED"@en ] .
This separation of the concept of the supplier, the redaction status and the text label gives us extra flexibility. For example, in some cases it may be acceptable to publish information that the same supplier was paid in return for multiple different services without publishing the identity of the supplier. In such situations the generated internal supplier URI can be reused for each relevant payment. If the co-identity of suppliers is also to be suppressed then a different URI would be created for each payment instance.
It is also possible further annotate the redaction with explanatory information, date of redaction and so forth. We recommend using DC Terms for this.
Technical Note. In some cases this approach to redaction will mean that a resource is used (to represent the redaction) in place of what would normally be a literal (e.g. a string or a number). In RDF and OWL Full semantics this is legal, a resource can denote any value including literal values. However, some data validators that impose stronger constraints or heuristic checks will warn about such substitutions and may need modification in order the run over data include redactions. Alternative approaches to redaction which avoid this problem are possible but they create greater problems with merging of datasets.
Extensions and well-formedness
RDF uses an open world, schemaless approach to modelling which makes it easy extend and add additional information using other vocabularies. For example, an authority which wished to show how the departments making the payments are grouped into higher organizational structures such as “Directorates” can do so (using the Organization ontology in that case) without needing to modify the payments ontology. Similarly annotations to explain the nature of a payment, to link it to an associated Freedom of Information request or to link it to source agencies that supplied the data can all be added using local or shared vocabularies and such annotations can be preserved through any RDF processing chain.
Conversely payments information is published with a wide range of levels of detail and the payments ontology is designed to permit information to be omitted from any given dataset. In the ontology itself the only constraints declared are that Payments must have at least one date, payer and payee. This means it is possible to publish data at only the payments level with no expenditure analysis. Note that since date is represented as a time interval rather than a specific instant the constraint of requiring a date is not strong, it is possible to publish at quarter, year or other resolutions.
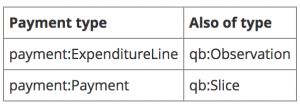
Technical Note on Data Cubes. The mapping of the payments ontology to data cubes assumes that the data is a collection of expenditure analysis lines grouped into payments so the data structure definition for the cube requires that the data include ExpenditureLines with an associated expenditureCode and netAmount. In the event that a publisher wishes to offer only payment level information but still treat the data as a complete data cube then an alternative data structure definition should be attached to the dataset, such as:
eg:PaymentsOnlyStructure a qb:DataStructureDefinition;
rdfs:label "payments-only structure"@en;
rdfs:comment "The structure of a cube containing only payments level information.";
qb:component
[qb:dimension payment:payer],
[qb:dimension payment:payee],
[qb:dimension payment:date],
[qb:measure payment:totalNetAmount],
[qb:attribute payment:currency] .
For inter-operation with data cube vocabulary it is recommend that publishers include the additional type information inferable from the vocabulary:
Aggregations
One other useful form of extension is to create slices which group subsets of the data for the purposes of aggregation. For example to represent the total spend from a given payer organization department within a given calendar month one might define:
eg:paymentByDeptPeriod a qb:SliceKey;
rdfs:label "Slice aggregating across suppliers and expenditure codes"@en;
qb:componentProperty payment:payee, payment:date, payment:unit .
eg:PaymentByDeptPeriod a rdfs:Class, owl:Class;
rdfs:label "Payment by Department over some defined period"@en;
rdfs:subClassOf qb:Slice .
The slices themselves then look like:
<slice-1234> a qb:Slice, eg:PaymentByDeptPeriod;
qb:sliceStructure eg:paymentByDeptPeriod;
payment:payee eg:MyOrganization;
payment:date <https://reference.data.gov.uk/id/month/1>;
payment:unit eg:MySubunit;
payment:totalNetAmount '456789.00'^^xsd:decimal;
qb:observation <expenditure-1>, <expenditure-2>, <expenditure-3>, ... .
Dataset metadata
Apart from the payments and expenditure lines themselves the other element in the ontology is a first class representation of the data set itself. The payments dataset defines the structure of the data and indicates the top level payments, then each individual expenditure line points back to the data that contains it. In addition, the payments ontology defines one attribute, the currency of the payment. The attachment level of this attribute is left open in the payments ontology. For the applications within UK local government we expect the attribute to be attached at the dataset level.
Thus a minimum declaration of a dataset looks like:
<dataset-uri> a payment:PaymentDataset ;
rdfs:label "Spend data for X for period P"@en ;
qb:structure payment:payments-with-expenditure-structure ;
qb:sliceKey payment:payment-slice ;
payment:currency <https://dbpedia.org/resource/Pound_sterling> ;
qb:slice <payment1>, <payment2> ... .
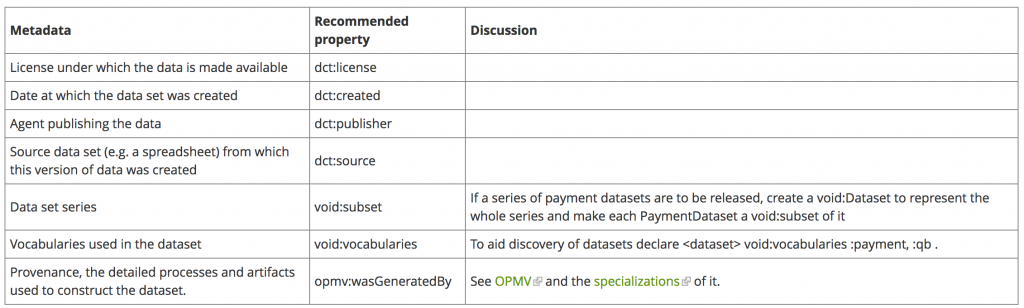
However, as illustrated in the worked example it is good practice to attach additional metadata to the data set. In particular:
APIs
Using the Linked Data API it is easy to wrap a RESTful web API over a set of data published according to the payments ontology.
A useful set of patterns is:
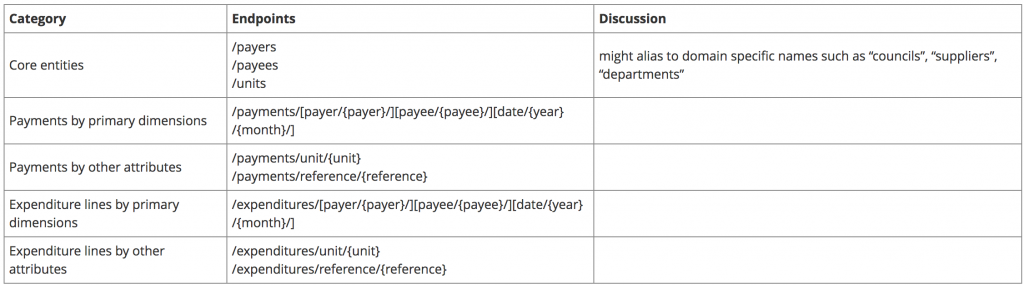
The URI fragments in {…} can be any unique identifier for the corresponding entity. A consumer of the API can discover these starting from the entity endpoints. One option is to use a URL-encoded version of the entity URI, another more human readable option, is to include short identifier strings in the dataset (e.g. using skos:notation or a local extension vocabulary).
Acknowledgements
The LeGSB/LGG work which forms the basis of this ontology was initiated, driven and guided by Paul Davidson.
Many groups participated in the workshops and discussions involved. We gratefully acknowledge the contributions to these from various Local Authorities, data.gov.uk, Local Government Association, SOCITM, esd-Toolkit, CIPFA, Ordnance Survey, Office of National Statistics, Department for Communities and Local Government, Talis and Epimorphics Ltd.
A first draft of the ontology was developed by Jeni Tennison who provided invaluable support and advice.
1 It is technically possible to publish a payments data set using only blank nodes for expenditures and/or payments. However, the value of being able to link to and externally annotate the items would then be lost so we recommend using concrete URIs for such data.
Appendix: Mapping for the Local Government Group spending data template
A separate guide to applying the ontology specifically for UK Local Government spend will be developed, targeted at a less specialist audience. Once that is complete this appendix will be redundant and may be removed.
The Local Government Group have published recommendations and an associated data template showing how UK Local Authorities should publish spending data. We show here how that template maps to the payments ontology.
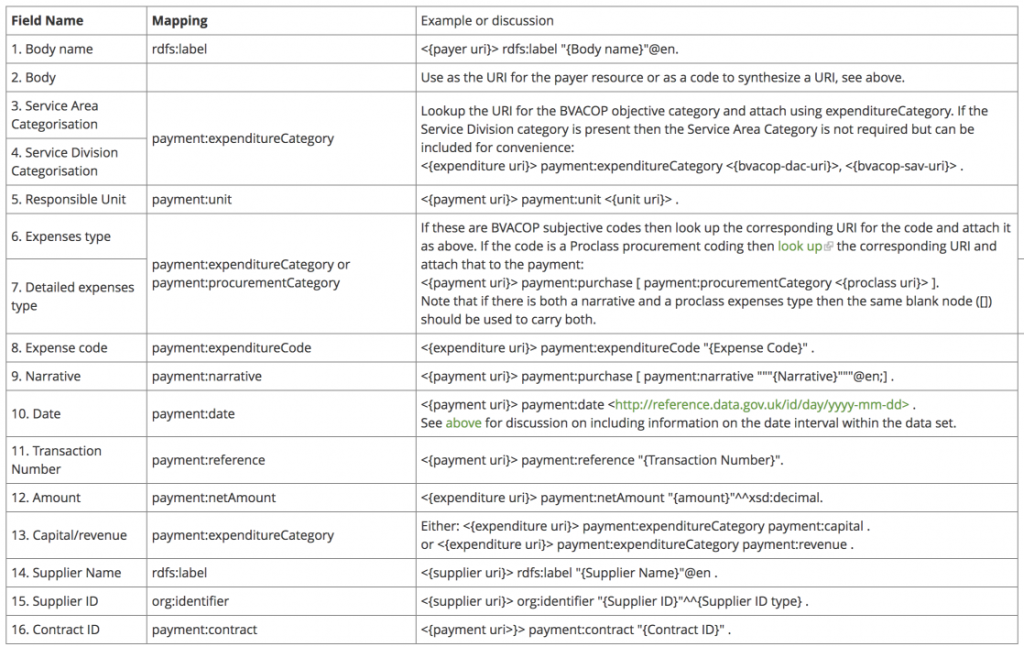
As well as the field by field mappings we need to construct appropriate resources (URIs) to which those fields will be attached:
For the overall dataset create an appropriate URI <{data set}>for the dataset and attach metadata to it as described in the guide above.
For each distinct payment in the data set (distinct Transaction number) create a URI for the Payment <{payment uri}> using the guidelines above, attaching it to the data set using:
<{payment uri}> a payment:Payment ;
rdfs:label "Payment {Transaction number}"@en .
<{data set}> qb:slice <{payment}> .
For each line in the data set create an expenditure line URI <{expenditure uri}> using the above guidelines and attach it to the dataset and to the payment using:
<{expenditure uri}>
a payment:ExpenditureLine;
rdfs:label "Expenditure line {n}"@en ;
payment:payment <{payment uri}> ;
qb:dataset <{data set}> .
<{payment}> payment:expenditureLine <{expenditure uri}> .
For the payer organization use the Body field if it is a URI else create a URI for the organization using the Body field information:
<{payer uri}> a org:FormalOrganization;
rdfs:label "{Body Name}"@en .
For each unit in the payer organization mentioned in the data set create or locate a URI for the unit <{unit uri}> using the above guidelines:
<{unit uri}>
a org:OrganizationalUnit;
rdfs:label "{Responsible Unit}"@en ;
org:unitOf <{payer uri}> .
<{payer uri}> org:hasUnit <{unit uri}> .
For each distinct Supplier organization locate or create an appropriate URI using the above guidelines:
<{supplier uri}> a org:Organization;
rdfs:label "{Supplier Name}"@en;
org:identifier "{Supplier ID}"^^{Supplier ID type} .
Where the data type for the supplier ID will be either registrars:CompanyRegistrationNum or registrars:CharityRegistrationNum.
Then the mapping for the individual data template entries is straight forward:
#TechTalk