The Hybrid Store provides clients with a single unified query layer that can query across relational and JSON data in a Postgres database and RDF graph data in Apache Jena Fuseki server (or our own Podium).
This unique hybrid query implementation enables users to store high volume tabular or record data in a relational database, and complex interconnected metadata in a graph database while still retaining the ability to easily query across the two.

The Hybrid Store provides a solution that brings together the capabilities of both Apache Jena Fuseki and Postgres
Graph databases such as Apache Jena Fuseki excel at maintaining complex graph data structures in a schema-free environment; but they tend to perform poorly when dealing with large volumes of homogenous record data, especially for queries that return many records with many fields or columns per record.
Relational databases are ideally suited for large quantities of data with a regular shape, but the relational model and the constraints of having to specify a database schema can make it difficult to work with complex metadata structures and to incrementally develop and refine the metadata that goes with the record data.
Applications such as Earth Observation stores often need to manage both high volumes of record data such as time-stamped sensor observations and complex metadata such as the location of the sensor, the item it observes, the properties of that item that it measures, the sensor’s maintenance and deployment history and so on.
The Hybrid Store provides a solution that brings together the graph-management capabilities of Apache Jena Fuseki for metadata, and the high-volume relational and JSON record management capabilities of Postgres. A single query language allows developers and API users to construct queries that seamlessly cross relational and graph datastore and returns a unified result set with elements of data taken from either store or both.
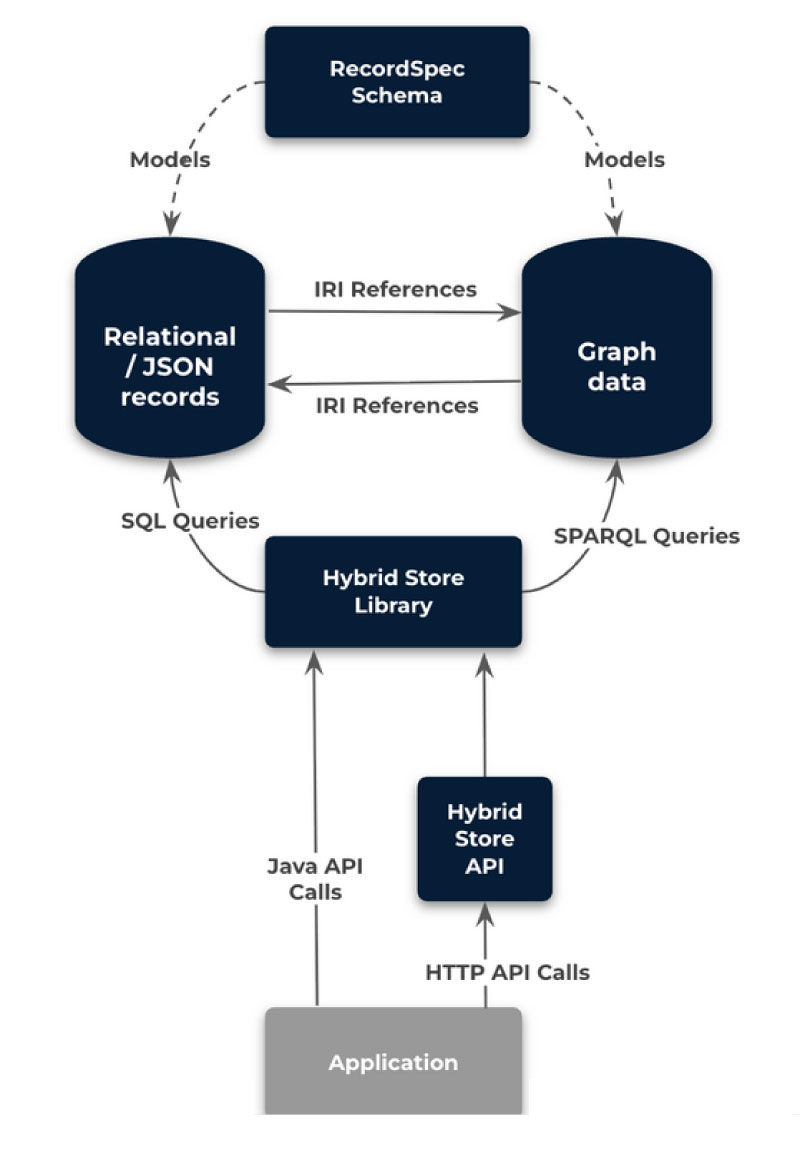
How the Hybrid Store Works
A simple schema language called RecordSpec is used to define the structure of the records stored in the relational database and the classes and properties of the nodes in the graph store.
Any record property in the relational store may reference any class of node in the graph store using its unique IRI reference, and vice versa.
The Hybrid Store Library allows developers to write queries using the RecordSpec schema as a guide and the implementation will seamlessly issue queries to either or both of the underlying stores as needed, unifying the results into a series of JSON trees.
The Hybrid Store API provides a simple web interface to the API allowing developers to POST their queries to a server and receive JSON results.

Who the Hybrid Store is for
Teams building modern data platforms, the Hybrid Store is the natural choice when you need the right tool for each type of data while still providing a single, coherent query experience.
The Hybrid Store is ideal for organisations that:
Work with both high-volume tabular data and complex interconnected metadata.

Want to expose simple, developer-friendly APIs over heterogeneous data without rewriting backend logic or tightly coupling applications to database engines.
Need to combine relational performance with the flexibility of graph models, without forcing all data into one technology.
Want a unified query layer that removes the operational and cognitive burden of managing separate query paths for relational and RDF stores.
Operate data-intensive platforms, especially where queries must join or traverse information stored across different database technologies.
