It can be a challenge to manage very high volumes of data from environmental, or other, sensor networks. Especially to do so while providing the high quality metadata needed to make the data FAIR (findable, accessible, interoperable, and reusable).
This is an area that we’ve been working in for some time, both as individuals and as a company – whether developing data models for sensor networks or building complete data publishing solutions for clients.
In the last few years we’ve faced the challenge of how to publish very large archives of data such as the Environment Agency’s historic archive of hydrological data – spanning thousands of sites and often more than 50 years of history with high resolution sampling.
This challenge has spurred us to extend our tooling to allow us to combine metadata from a linked data store with data from scalable noSQL (Apache Cassandra) and SQL stores. This gives us the best of both worlds. The linked data store gives us flexibility in how we describe the things being measured and the available features of interest, sampling stations and measurement time series while meeting FAIR principles. The bulk data storage gives us the performance and scalability to handle very large data sets cost-effectively. Our API tooling allows us to provide a simple API onto both the data and metadata without our users needing to be aware of the underlying storage partitioning.
This approach has allowed us to build a new version of the Environment Agency’s Hydrology Service that scales to 5 billion measurements across thousands of measurement stations. While delivering good retrieval performance.
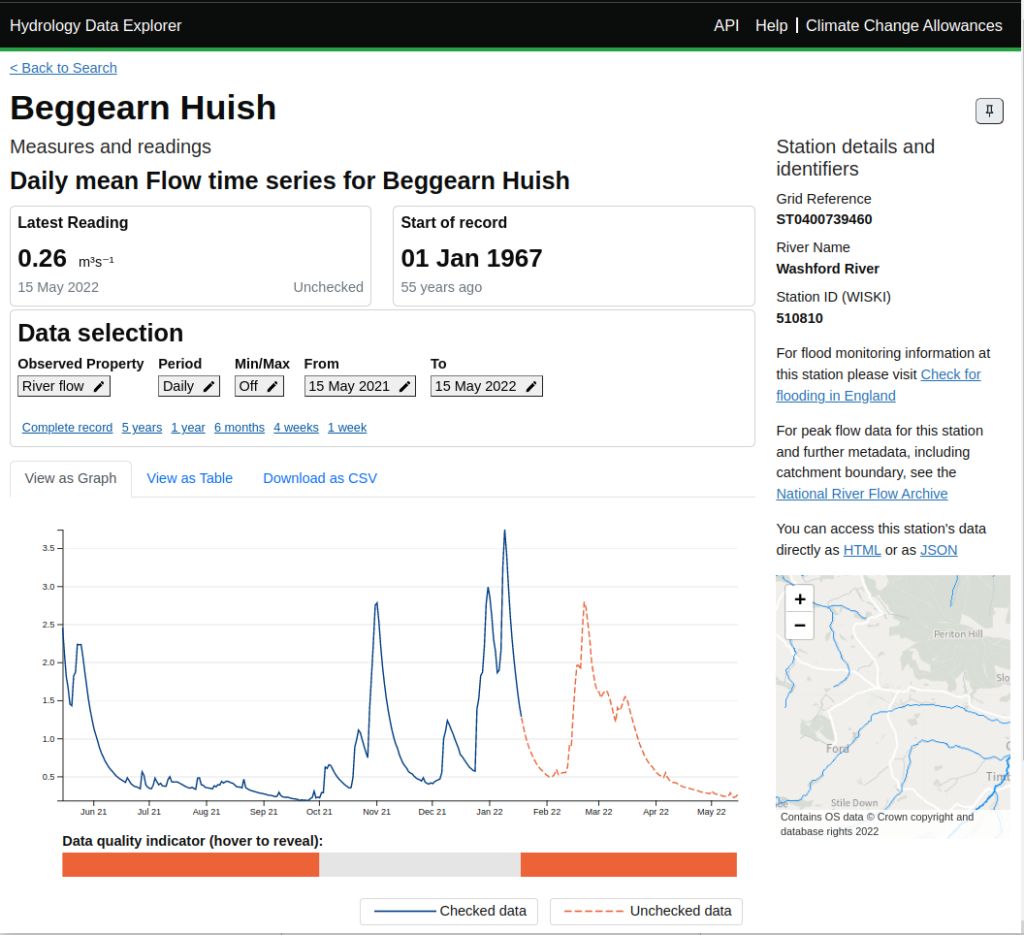
We are really proud of what we’ve built and have been working to make this available for reuse as a packaged solution, which we’re calling the Agora Measurement Store.
If this is of interest, we’d love to hear from you. For more information see our initial Agora Measurement Store page.