
When we last experimented with Large Language Models (LLMs), and their embodiment in agents like ChatGPT, we had mixed results. Applying ChatGPT-3, as it was then, to the problem of data modelling and ontology generation we found it impressive but ultimately the results were superficial and of limited use for practical modelling work in its then current state.
Since then the world of LLM-based agents has continued to develop in leaps and bounds. We have ever larger and powerful LLMs, a rich space of open source or open access LLMs, and more powerful tools for creating agents on top of them.
At Epimorphics we are all about data – connecting data and making it more easily available – whether within an organisation or open to everyone. But to have an effect with that data you need people to be able to find it, access it, and analyse it to solve problems.
So a natural question is whether an AI assistant could help to democratise access to data and data analysis tools. To lower the barrier to consuming the kind of data we publish and putting it to work.
We recently had the chance to explore just that. Working with the Environment Agency, we looked at whether an AI Assistant could help users of our Hydrology service to access and analyse data on the water environment.
Our approach
The first thing to be clear on is that you probably don’t want an LLM to analyse data directly. Not only is the typical data set we are interested in too big to fit in the typical LLM context window, but LLMs, for all their facility with generating text, are barely able to do arithmetic reliably let alone calculate something like a correlation coefficient.
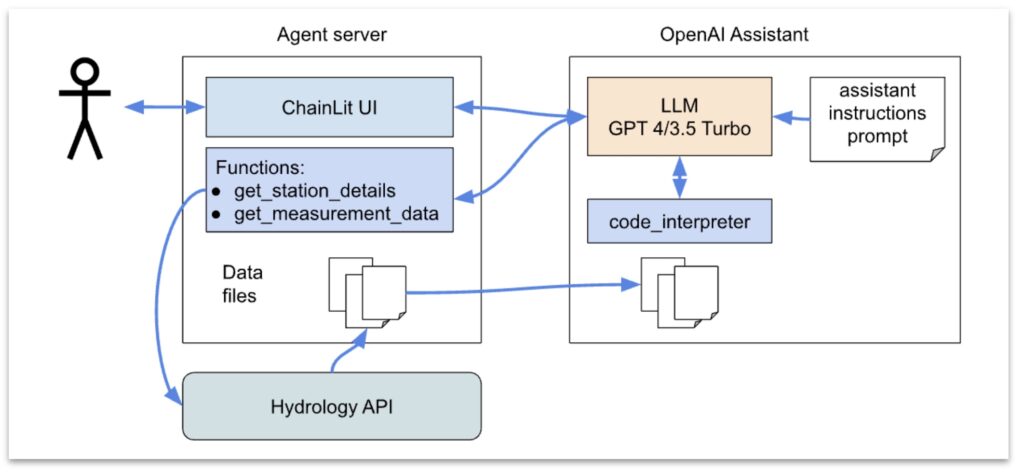
Instead the approach is to provide an LLM agent with tools that it can use to locate and fetch data and then exploit their ability with code generation to get them to write programs to do the analysis and visualisation of the data. So the manipulations are all scalable, reliable and inspectable.
In recent months, support for this sort of approach has been transformed. In our experiments, we used the OpenAI Assistant API but open source tools are improving fast and LangChain Pandas Dataframe agent looks like a promising alternative.
To create an AI data assistant for hydrology we need several elements.
First, we want it to be able to reliably find the hydrology station or stations we are interested in. Out of the box, ChatGPT or even Bing with its internet access, can’t reliably find the identity for “well known” gauging stations let alone temporary water quality stations. To solve this we provide it with a tool to lookup metadata on stations through text search. This is already supported by the hydrology API, and the text index includes terms such as the station identifier and associated rivers. So all we need is a simple Python function to call the API and then package that up with some metadata to describe what the function does:
{
"type": "function",
"function": {
"name": "get_station_details",
"description": "Get the hydrology station details given an identifier such as name or wiskiID",
"parameters": {
"type": "object",
"properties": {
"identifier": {
"type": "string",
"description": "Station identifier such as name or wiskiID",
},
},
"required": ["identifier"],
},
},
}Similarly we can define a tool to download data from the API for some station it has identified and for some time period. We download the data to our agent first and then upload it to the conversion “thread” in the OpenAI Assistant so that the assistant can access the data files from a code sandbox. A python code sandbox is a standard tool built into the assistant platform, so we can simply request that option be included when creating the assistant.
To wire these pieces together we then need a set of instructions, again in English, to guide the LLM in what it is to do. These are essentially an initial prompt given to the LLM. We opted for simple high level instructions without any worked examples (so called “zero-shot”).
You are a hydrology data retriever and analyser. Use the provided functions to answer user queries.
Don’t make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous.
If you don’t know the measurement identifier first obtain station details using the get_station_details function.
This returns a json structure which includes a label for the station and a list of measures that are available.
When asked to list stations use only the results from get_station_details function, do not include stations you may know about from other sources.
When summarising a station give their label and a summary of the parameters available as measurements.
Once you have the @id of the measure use that @id in the get_measurement_data function to retrieve the data.
The data that you receive from get_measurement_data function is always in text/csv format and you will be provided with a file id to use.
Never embed images in your text responses.
Finally we package all this up by creating an Assistant instance through the OpenAI API and then link to a driver UI, we used the ChainLit open source tooling to create a conversational style interface.
And it works!
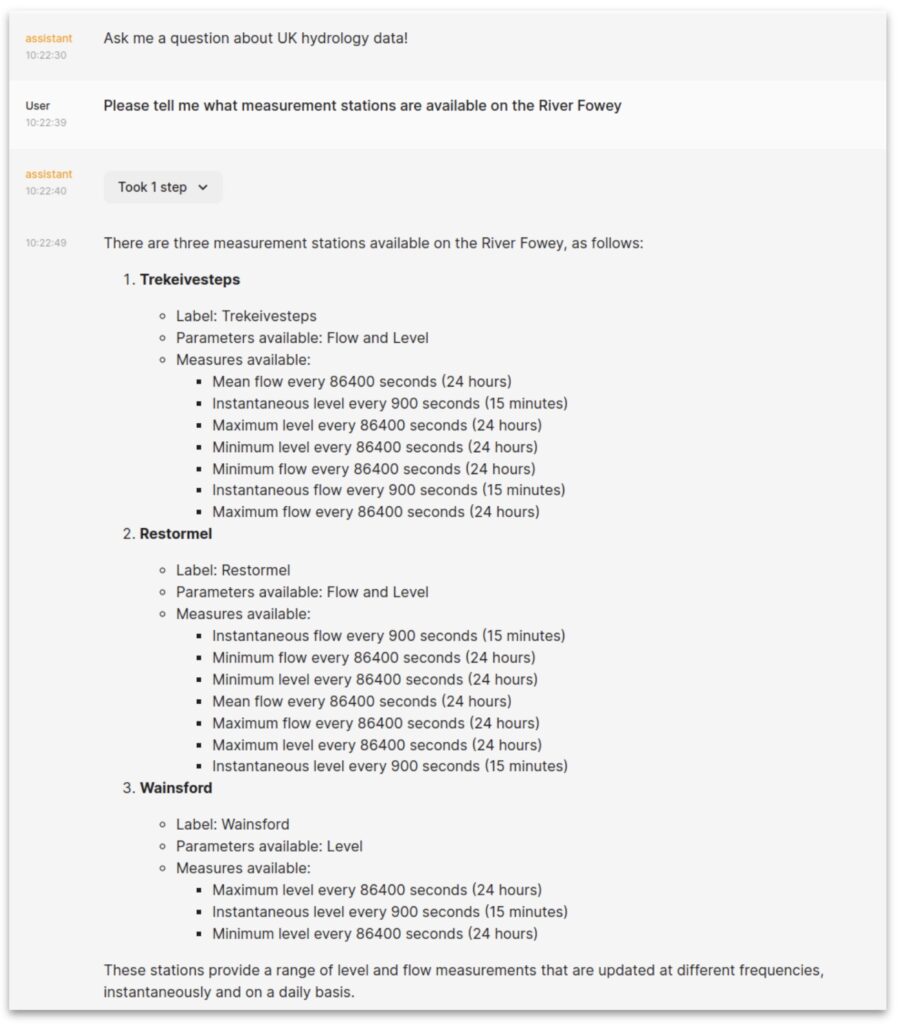
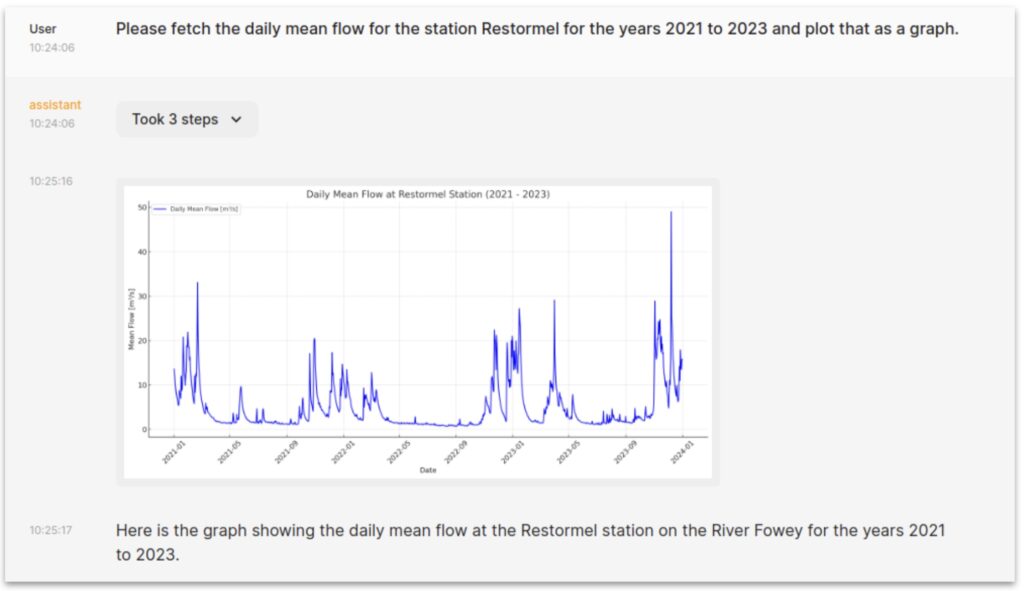
The Good
This is really powerful. Without being a coding expert or familiar with the hydrology API you can find measurement stations, fetch and display data and analyse it. Doing things like looking for trends or correlating patterns between different sites.
It’s also very flexible. We have told it nothing about the specifics of what packages are good to use for data analysis but are relying on the large volume of python coding examples in the training data for the LLM. It seems to be able to make good use of e.g. pandas and statsmodels which in turn offer a vast range of analysis possibilities.
At least with the newer GPT models it is pretty good at correcting errors. If an analysis fails because some precondition wasn’t met it can often spot that and apply fixes. For example, in doing some correlation analysis, when it got failures due to alignment issues or missing values between two datasets, we’ve seen it automatically introduce sensible interpolation and realignment steps to enable the correlation calculation to go ahead.
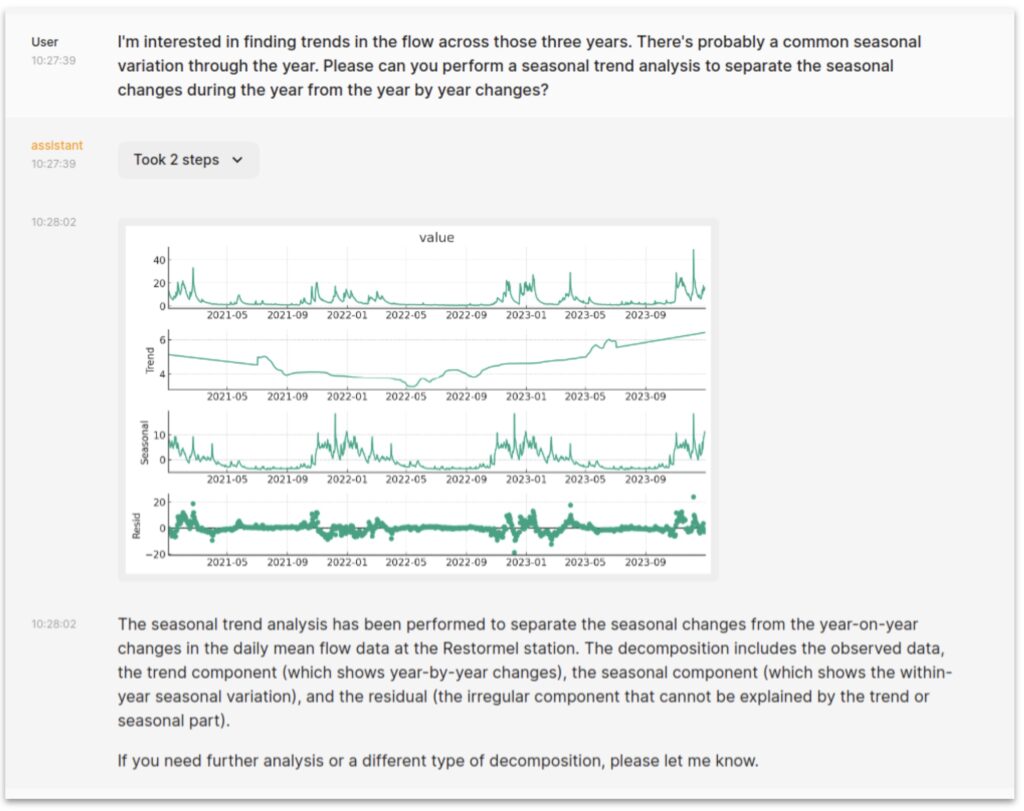
Finally, one nice thing about using LLMs this way is that we can inspect the details of how they have processed the data. For example, opening the “Took 2 steps” tab in the last example shows:
If you are not a python expert you may not recognise the specific package used there but at least you know exactly what it did and can seek assistance if you need it. Of course, you can always ask the assistant itself why it took the approach it did:

The Bad
There’s a lot of randomness in the results. At a presentational level the way it, for example, summarises the stations it has found, and the measurements available from them, varies considerably from run to run. Sometimes including full details with hyperlinks, sometimes providing a succinct summary and with widely varying formatting. This kind of thing could be made more consistent though a more detailed base set of instructions, with examples and format preferences.
More seriously it sometimes has “bad days” and seems unable to find analysis options it was previously robust at and needs more detailed prompts. We believe that OpenAI is continually making background model tweaks which might explain some of this and things settle down after a couple of tries, but it makes for an unpredictable experience.
It is also possible for the LLM to hallucinate. Given the architecture it can’t make up data or invent analysis results. However, when looking for stations it is the LLM which takes the results of the embedded station metadata search (a JSON response) and turns that into text to present back to the user. While GPT-4 turbo seems robust at this, we found GPT-3.5 turbo would sometimes make up stations that weren’t present in the return from our get_station_details tool. This was fixed by tuning the instructional prompt to ask it to use just that data from that tool and nothing else. However, it’s a good reminder that at heart the LLM is just making up text that is statistically likely to follow on from what it has seen, there’s no deep understanding here and you have to watch for such loopholes in how you instruct it.
Finally, using the OpenAI API with the most recent models is not cheap. With GPT-4 Turbo The above interactions cost about $0.60, 95% of which is the cost of the LLM model tokens. A full session exploring some data is generally longer and costs a few $. For a limited use commercial, private service that could work but if you want to provide such an assistant as a public service to help improve access to open data then those sort of costs are not viable.
We can bring the cost down eightfold by using the cheaper GPT 3.5 Turbo. This required some prompt tuning to reduce the hallucination effect but, once that was sorted, 3.5 Turbo seemed just as good on these sorts of examples and GPT-4 Turbo. Given recent history we would also expect the costs of these high end LLMs to drop another order of magnitude over the next year through both technology improvements and competition from many other players, including open source models. By that point the costs would even be viable for public services, provided good processes for fair use management are in place.
And the User Experience
The sort of conversational user interface we see with chat agents will not suit all tasks.
Graphical user interfaces have lots of advantages. It’s easier to ask what data is available for some area of the country by pointing to it on a map than by typing out a description of where you mean. If you want to visualise the effects of changing a parameter in your analysis, then an interactive tool with sliders and knobs may be more effective than having to type into a text box and wait for many seconds before you see the next graph.
Nevertheless, the chat interface does offer huge flexibility. The ability to ask the agent to fetch, analyse and present data via one short text prompt can be a lot easier than manually downloading data, configuring some general purpose interactive tool and learning to drive it.
It is also potentially great from an accessibility point of view.
Overall, we’re pretty excited by what’s possible here and keen to push the boundaries further.
Could we marry the AI assistant style with a better support for map based interactions to express what you are interested in, and visualise some of the results?
If you need a more interactive presentation can we use the AI assistant to set up bespoke interactive visualisations?
Can we use small, cheaper or open source models to achieve similar goals if they are well enough tuned for the coding task? Would it be possible to generate a training set to allow fine tuning of a smaller LLM to data analysis tasks?
Lots to think about!
We’re very grateful to Environment Agency for sponsoring this work.