
#TechTalk: URIs and URLs for linked data, is an old topic but one which keeps coming up in discussions so it seemed worth a refresher…
Why URLs at all?
Linked Data is all about helping people understand and combine data from different sources, or over time. For that to be possible we want to create persistent, resolvable identifiers for the entities and terms in our data so we and others can reuse them. The best way to do that is to use URLs.
If we see some data telling us that 6CC45BF4-13A2-4B94-FAB1-FFBEDFBE300A had a value of 0.131 at 2023-09-10T12:45:00 we are none the wiser. We can guess that the long string is a UUID and so probably a unique identifier for something, maybe a time series, but without more context we don’t know what. Whereas if, instead the data says that the value applied to:
http://environment.data.gov.uk/hydrology/id/measures/bf679fd0-8d8f-4815-a569-ec798d81f324-level-max-86400-m-qualified then we are much better off. Firstly we can infer something about the provenance of reference from the owner of the domain – looks like it’s from or relates to Defra’s Hydrology data service. We might even guess that it relates to maximum (river) levels. But because that link is a URL we can just click on it and get a definition of that time series which in turn links to the measurement station from which it was taken.
Reusing persistent identifiers helps us combine data. Making those identifiers resolvable means we can look them up and understand the data so we know what it is we are combining. For UK Government data then URLs are the adopted open standard for such identifiers.
The FAIR principles have grown in acceptance across key data communities, they emphasise machine-usability because humans increasingly rely on technology support to deal with data as a result of the increase in volume, complexity, and creation speed of data. Practical implementations of the FAIR principles rely on persistent resolvable identifiers. These are key elements of making data FAIR – addressing the goals of Accessible and Interoperable.
Or, more pithily, linked data – data you can click on.
We often talk about URIs rather than URLs, Identifiers rather than Locators. URIs can encompass other identifier schemes like uuid: and urn: which follow the same syntax but can’t be looked up. We’re using URL here to emphasise that using a scheme like http(s) gives us the option to make them resolvable.
But our data isn’t open
If you are a medium to large organisation with different groups generating and consuming data then you face the same issues and reusing persistent identifiers in your data sets will make them easier to integrate and understand.
Many customers we work with recognise this and want some form of persistent identifier scheme that they can use internally, and making those reusable URLs based on some internal domain is just as useful within an organisation as it is in the open web. Even if you never share the identifiers with others. In practice many organisations work with networks of partners and suppliers with whom they want to exchange data and URLs make an excellent foundation for interoperability in such data exchange networks.
Even if you don’t plan to make the identifier URLs live and resolvable right now, planning so that they could be so in the future is good practice.
Do I care how the URIs are structured?
If you are just thinking of identifiers in data then you don’t necessarily care how they are structured, just so long as each is unique. However, even then giving some structure to the identifiers can be useful – some element of human readability really helps with development and debugging.
However, as soon as you want at least the option to have your identifiers resolve then you need to think about the structure of them to make routing and resolving easy. This dual process of combining data design with transport and network issues may seem strange at first but pays off.
A default pattern
The structure of a URI or UL is well known:

The core elements for identifier design are the authority (or host) part and the hierarchical path. When designing linked data URIs we find it helps to think of these components in two groups, as illustrated below:
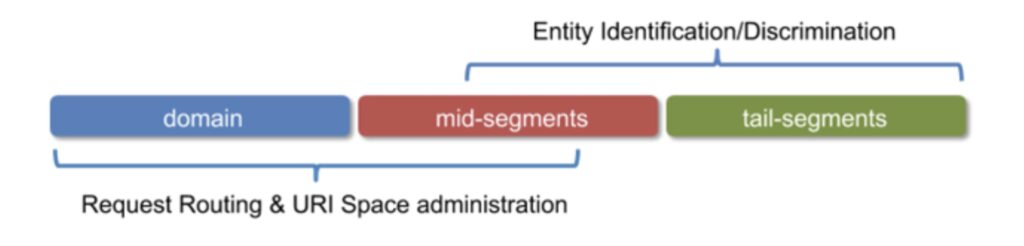
So a combination of the domain and the leading path segments define a high level partitioning of the URL space which affects routing of requests and administration. The core identifier information resides in the trailing path segments.
A good set of patterns is given in the revised advice from the UK Government Linked Data working group.
For request routing and URI space administration use something like:
https://{domain}{/collection*}[/{type}]/{rhs-id-pattern}The choice of domain can be used to convey authority and branding but needs to be a stable DNS domain that you have access to. You will want that to persist.
The collection segments give you some top level partitioning so that different groups or data sources can share the same root domain but don’t necessarily have to share the same infrastructure. A simple proxy can route requests to different collections to different organisations and resolvers. For example, in our earlier example hydrology is the collection name and the central Defra proxies route all requests to that subdomain to kubernetes infrastructure run by ourselves, other suppliers coexist in the same identifier space by using separate subdomains.
Finally the type segment is optional but is conventionally one of id, def, data or doc. See below for more discussion on that.
What about https?
This is surprisingly controversial. We clearly want all requests to retrieve the metadata for our identifiers to be secure against “man in the middle” attacks which might modify the data. So the metadata should be transported over https. This doesn’t necessarily mean that the identifiers in the data should use https. They could be http identifiers but actual dereferencing can be directed to transport over https using modern infrastructure like HSTS/UIR. Indeed Tim Berners-Lee strongly advocates keeping to http for identifiers and let the web infrastructure handle the security transparently. For this reason identifiers used in the W3C standards will remain http and we don’t need to rewrite all our data to point to https versions.
All that said, a source of errors in Linked Data is when a developer follows links in their browser to find the term they want, and then cut/pastes the URL from the browser bar into their data. In a typically modern browser this means they’ll cut/paste the https version without realising the reference was actually to http. To avoid this inconvenience we suggest then when starting out on new URL deployments using https is the more practical approach.
Are these id/def/data things necessary?
The type element in the pattern was introduced by the original UK Government URI advice. The notion is that id URLs denote identifiers for entities in the world, def URLs denote terms in ontologies and data URLs denote collections of data or individual data items.
For some people this distinction seems unnecessary and they question this part of the pattern – certainly the updated guidance makes it optional.
The original reason for the distinction is rooted in an infamous issue in web architecture called http-range-14. Some find this too philosophical to worry about. While the resolution does also provide a way to separate metadata for the thing (such as a sampling station) from metadata about the data record (such as who last updated our record of that sampling station) there are other ways to achieve that.
Real world things can’t be sent over the wire so instead of responding to a URL for one with a “200 OK” response, the argument is that you should respond with a “303 See Other” meaning “I can’t send the thing itself so here’s some metadata about it instead”. The convention enshrined in the UK Government data patterns is that a request to an id URL will redirect to a doc URL.
the “http-range-14” debate
Nevertheless, we do find the type element useful for a number of reasons. Firstly, it helps with human readability. Yes the identifiers are really there for the machine but there are times when people have to work with the raw data and some element of human readability helps. Secondly, it helps with request routing. It’s not unusual for us to have different infrastructure for those three sets of terms – a reference data management system for the def terms, a linked data service for the id terms and possibly some scalable data store for the data terms. So having a left-hand side URL segment to use for that routing is really helpful.
Identifier patterns and APIs
Now we have the basic patterns and all the routing done we just need to tag some sort of unique ID on the end of our URLs and we’re done. Right?
Well yes, and no. There’s no fundamental reason why you can’t just append a unique ID and not have any further structure to your URLs. But again we find structure useful, both for human readability and for compatibility with APIs.
It’s conventional in REST APIs to have a pattern such as:
https://environment.data.gov.uk/hydrology/id/stationsbe an API which returns a list of stations and then the API for getting data on an individual station would be:
https://environment.data.gov.uk/hydrology/id/stations/{id}So following this pattern in our identifier construction enables us to have an API which both provides the resolver for our identifier URLs and which supports listing (and filtering) our collections of data.
So we tend use a right-hand side pattern along the lines:
./id[/{concept}/{key}]*/{concept}/{key}Where concept is a short name for the type of entities and key is some identifier for it.
The optional repeated {concept}/{key} prefix is used to allow for resources which are intrinsically sub-parts of some parent resource such as:
./road/M5
./road/M5/junction/24
./road/M5/junction/24/exit-slip/southboundDon’t sweat about the choice of label for the concept, e.g. in cases where there are multiple types. Those elements are just there for readability and to support an API, not there to convey formal semantics.
For the key then often there will be some “natural” domain identifier you can use or you can mint a new one using a variety of tools for generating unique keys, ranging from sequence numbers to UUIDs. One pattern we often find helpful when there are multiple natural keys, or we don’t want to expose the natural keys in the URLs, is to generate a hash of the keys and encode that hash in the URL.
A similar pattern works for the other types, e.g.:
./def/{/vocabulary*}/{term}Where the vocabulary segments identify the vocabulary or ontology and the term segment identifies the term in the ontology in the obvious way.
The term segment is generally a human readable name for the concept and can be based on a normalised version of the preferred human readable label used for presentation. In some domains (for example, WikiData and OBO) the convention is to use an opaque identifier here as well (c.f. the keys used in URI sets). This is either for ease of management or so that the labels are language neutral and don’t disempower users whose first language differs from that used by the vocabulary authors. On balance, when users are primarily speakers of the same language, we prefer human readable vocabulary and term segments.
Wrapping up
None of these patterns are inviolate. If you have specific requirements that don’t fit then pick something different. But hopefully having some default patterns, and ones that have stood the test of time, are helpful at least as a starting point.